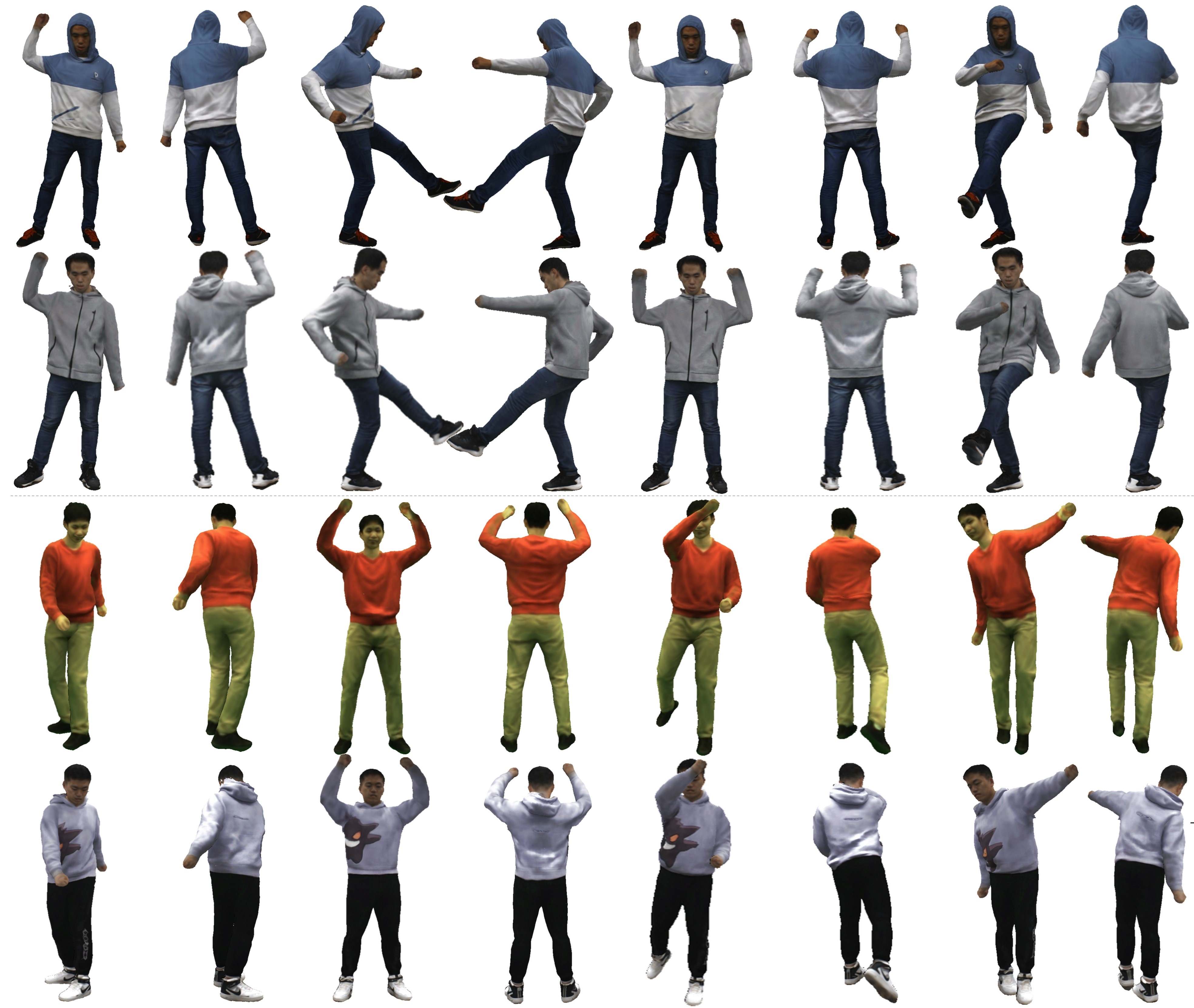We propose PoseVocab, a novel pose encoding method for high-fidelity human avatar modeling.
Creating pose-driven human avatars is about modeling the mapping from the low-frequency driving pose to high-frequency dynamic human appearances, so an effective pose encoding method that can encode high-fidelity human details is essential to human avatar modeling.
To this end, we present PoseVocab, a novel pose encoding method that encourages the network to discover the optimal pose embeddings for learning the dynamic human appearance.
Given multi-view RGB videos of a character, PoseVocab constructs key poses and latent embeddings based on the training poses.
To achieve pose generalization and temporal consistency, we sample key rotations in so(3) of each joint rather than the global pose vectors, and assign a pose embedding to each sampled key rotation.
These joint-structured pose embeddings not only encode the dynamic appearances under different key poses, but also factorize the global pose embedding into joint-structured ones to better learn the appearance variation related to the motion of each joint.
To improve the representation ability of the pose embedding while maintaining memory efficiency, we introduce feature lines, a compact yet effective 3D representation, to model more fine-grained details of human appearances.
Furthermore, given a query pose and a spatial position, a hierarchical query strategy is introduced to interpolate pose embeddings and acquire the conditional pose feature for dynamic human synthesis.
Overall, PoseVocab effectively encodes the dynamic details of human appearance and enables realistic and generalized animation under novel poses.
Experiments show that our method outperforms other state-of-the-art baselines both qualitatively and quantitatively in terms of synthesis quality.
Method
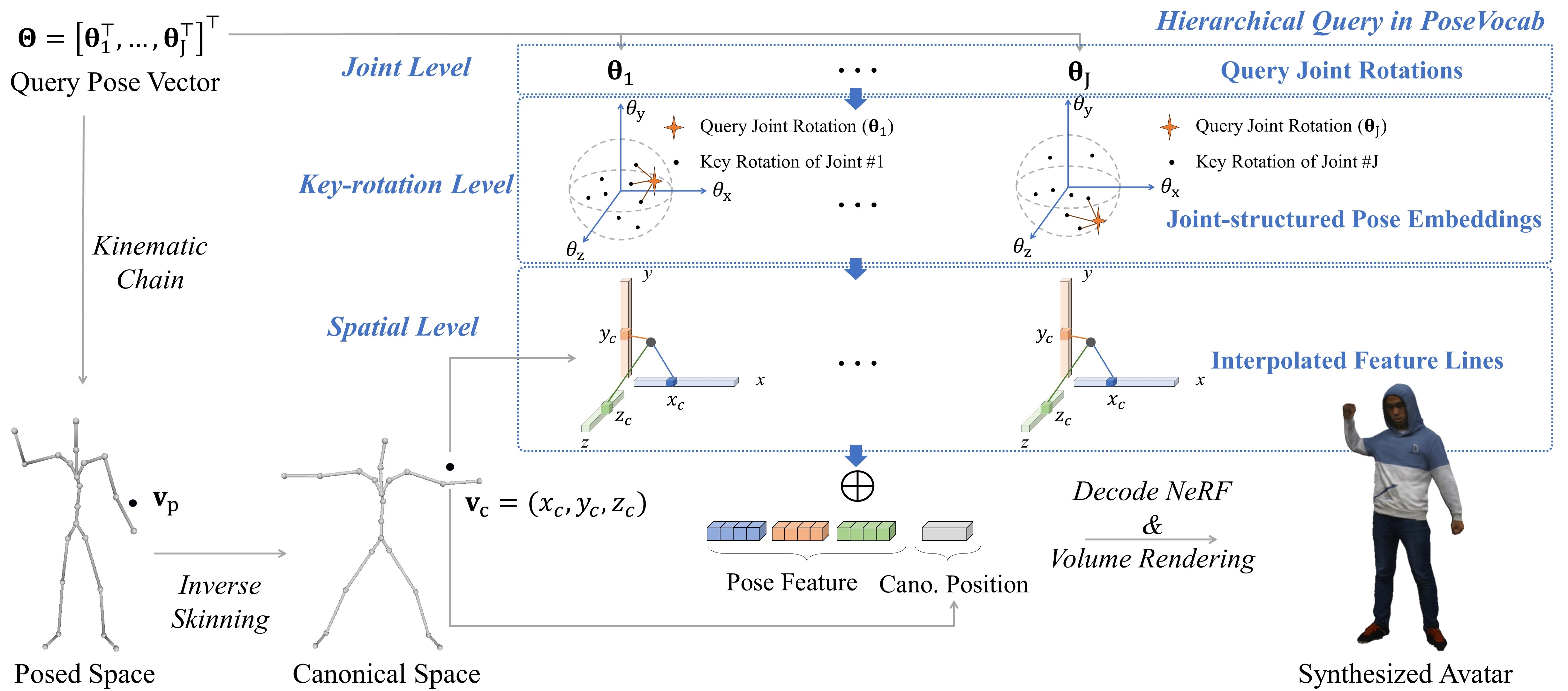
Fig 1. Overview of the representation of PoseVocab. PoseVocab is constructed based on the training poses by sampling
the key rotations in 𝑠𝑜 (3) of each joint and assigning a pose embedding for each key rotation. These joint-structured pose
embeddings encode the dynamic appearance of the character under various poses. Given a query pose and 3D position, we
hierarchically interpolate pose embeddings in joint, key-rotation and spatial levels to acquire the conditional pose feature,
which is fed into an MLP to decode the radiance field, eventually synthesizing the high-fidelity human avatar via volumerendering.
Results
Fig 2. Animated avatars with high-fidelity pose-dependent dynamic details by our method.
Comparison
Fig 3. Qualitative comparison against SLRF, TAVA and ARAH.
Demo Video
Citation
@inproceedings{li2023posevocab,
title={PoseVocab: Learning Joint-structured Pose Embeddings for Human Avatar Modeling},
author={Li, Zhe and Zheng, Zerong and Liu, Yuxiao and Zhou, Boyao and Liu, Yebin},
booktitle={ACM SIGGRAPH Conference Proceedings},
year={2023}
}